
Beyond spreadsheets: Automated classification of emails, documents and images from a library of files
patrick.weissg…
Structured data extraction—the process of transforming unstructured text, images, or documents into organized formats like JSON or databases—has undergone a revolution with large language models (LLMs). Here’s how AI reshapes this field and what you need to consider.
Traditional Methods vs. Modern AI
Earlier Workflows:
- Rule-based systems: Relied on regex, template matching, or manual coding to extract fields like dates or names from documents.
- NLP pipelines: Combined OCR for text recognition with techniques like Named Entity Recognition (NER) to identify entities.
- Human-in-the-loop: Required manual validation for complex layouts (e.g., complex tables).
Limitations:
- Rigid rules failed with varied document formats.
- High error rates in handwritten text or low-quality scans.
- Scalability issues for large datasets.
Modern AI-Driven Extraction:
- LLMs with Context: Models like GPT-4 or Llama-3 analyze unstructured text directly, inferring structure without predefined rules.
- Retrieval-Augmented Generation (RAG):
- Convert documents/text into embeddings (e.g., using OpenAI’s text-embedding-3-large).
- Retrieve relevant context from vector databases (e.g., Chroma).
- Generate structured outputs via LLM prompts (e.g., LangChain’s RetrievalQA).
- Specialized Tools: Frameworks like ExtractiVerse enable JSON/CSV output via Pydantic schemas.
Key Considerations for AI-Driven Extraction
| Factor | Challenges & Solutions |
| PII Handling | We use local LLMs and on-prem deployment to avoid exposing sensitive and personally identifiable data. |
| OCR Integration | Passing extracted text after OCR step to LLMs to process scanned PDFs/images. |
| Table Extraction | Here using LLMs with layout awareness parse tabular data accurately. |
| Image/PDF Parsing | Vision-language models extract text/graphics from complex documents. |
| Data Privacy | We ensure that tools are GDPR/ISO-compliant with encrypted processing and access control, and only save extracted data (not whole file). |
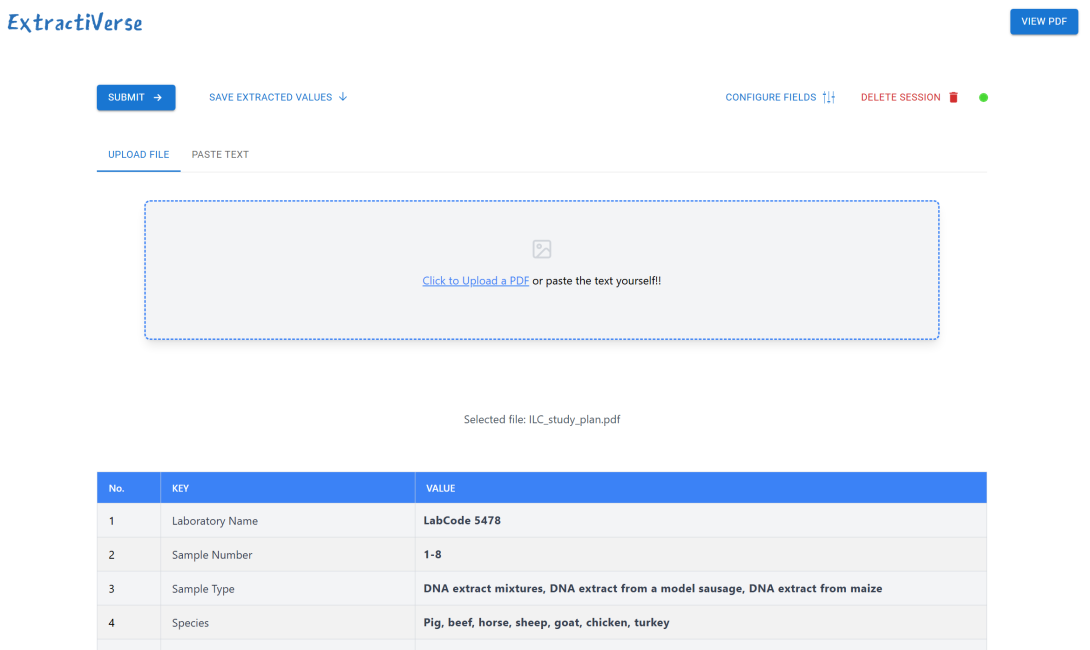
Use Case using PROLab and ExtractiVerse: AI-Driven Lab Performance Benchmarking with Procedural Metadata
Scenario
A network of 200 clinical labs participates in a interlaboratory study. Each lab:
- Submits:
- Measurement data (e.g., spectra or chromatograms and analyte values from 50 patient samples)
- Procedural metadata (equipment used, calibration logs, sample prep steps, technician notes) via structured forms or free-text reports
- Goal: Benchmark the performance while identifying procedural root causes for deviations
Workflow
- Automated Data Extraction
- Structured data: Lab results (numerical values, units) parsed via PROLab family of products
- Unstructured metadata:
- NLP extracts key procedural steps (e.g., “centrifugation at 3,000 RPM for 10 mins”) from text/PDFs
- Vision models analyze instrument calibration logs in scanned documents
- Z-Score Calculation
- Consensus mean (μ) and SD (σ) derived from all labs’ measurement data
- Lab-specific Z-score:
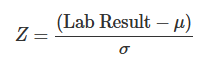
- Performance tiers:
- |Z| ≤ 2: Satisfactory
- 2 < |Z| < 3: Investigate potential problems
- |Z| ≥ 3: Critical error (e.g., calibration failure)
- AI-Powered Root Cause Analysis
- Procedural clustering: Labs grouped by equipment type/prep methods (e.g., “Lab A used HPLC vs. Lab B’s spectrophotometry”)
- Pattern detection:
- Labs skipping “daily calibration” had 2.3× higher Z-score variance
- Samples centrifuged <5 mins showed 15% higher false positives
- Feedback to labs:
"Your Z-score: -2.7 (elevated variance). 92% of labs with similar equipment performed better.
1. Recommended: Recalibrate Device X weekly (vs. current monthly)
2. Extend centrifugation to 8 mins (per SOP Section 4.2)"
Why This Matters
- Smarter Audit process: The audit process is reduced from several weeks to hours.
- Transparency: Labs see how procedural choices impact scores (e.g., “Using Method Y reduces Z-score variance by 40%”)
- Precision: SD adjusts dynamically as labs adopt best practices, tightening benchmarks
- Compliance: Flags labs using deprecated methods (e.g., “Stop using Device Z – 80% phased out in 2024”)
Tools like ExtractiVerse and PROLab enable this integration, turning raw data + protocols into actionable performance insights.